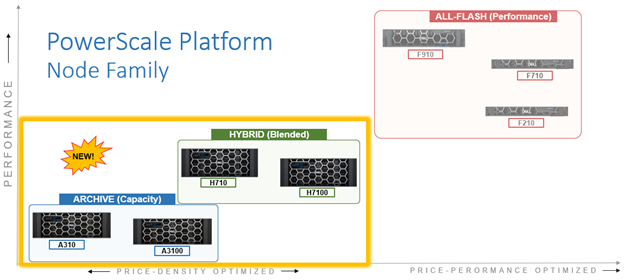
In this article, we’ll take a more in-depth look at the new PowerScale H710 and H7100 hardware platforms that were released last week. Here’s where these new systems sit in the current hardware hierarchy:
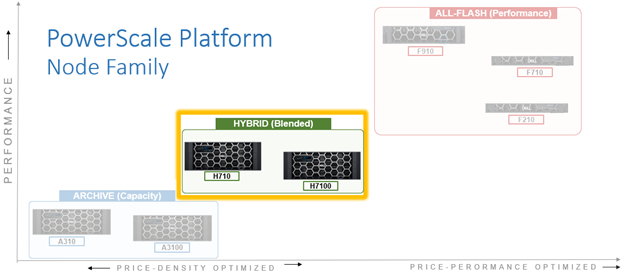
As such, the PowerScale H710 and H7100 are the workhorses of the PowerScale portfolio. Built for general-purpose workloads, the H71x platforms offering flexibility and scalability for a broad range of applications including home directories, file shares, generative AI, editing and post-production media workflows, and medical PACS and genomic data with efficient tiering.
Representing the mid-tier, the H710 and H7100 both utilize a single-socket Zeon processor with 384GB of memory and fifteen (H710) or twenty hard drives per node respectively, plus SSDs for metadata/caching – and with four nodes residing within a 4RU chassis. From an initial 4 node (1 chassis) starting point, H710 and H7100 clusters can be easily and non-disruptively scaled two nodes at a time up to a maximum of 252 nodes (63 chassis) per cluster.
The H71x modular platform is based on Dell’s ‘Infinity’ chassis. Each node’s compute module contains a single 16-core Intel Sapphire Rapids CPU running at 2.0 GHz and with 30MB of cache, plus 384GB of DDR5 DRAM. Front-End networking options include 10/25/40/100 GbE and with both 100Gb Ethernet or Infiniband as selectable options for the Back-End network.
As such, the new H71x core hardware specifications are as follows:
| Hardware Class | PowerScale H-Series (Hybrid) | |
| Model | H710 | H7100 |
| OS version | Requires OneFS 9.11 or above, and NFP 13.1 or greater.
BIOS based on Dell’s PowerBIOS |
Requires OneFS 9.11 or above, and NFP 13.1 or greater.
BIOS based on Dell’s PowerBIOS |
| Platform | Four nodes per 4RU chassis; upgradeable per pair; node-compatible with prior gens. | Four nodes per 4RU chassis; upgradeable per pair; node-compatible with prior gens. |
| CPU | 16 Cores @ 2.0GHz, 30MB Cache | 16 Cores @ 2.0GHz, 30MB Cache |
| Memory | 384GB DDR5 DRAM | 384GB DDR5 DRAM |
| Journal | M.2: 480GB NVMe with 3-cell battery backup (BBU) | M.2: 480GB NVMe with 3-cell battery backup (BBU) |
| Depth | Standard 36.7 inch chassis | Deep 42.2 inch chassis |
| Cluster size | Max of 63 chassis (252 nodes) per cluster. | Max of 63 chassis (252 nodes) per cluster. |
| Storage Drives | 60 per chassis (15 per node) | 80 per chassis (20 per node) |
| HDD capacities | 2TB,4TB, 8TB, 12TBTB, 16TB, 20TB, 24TB | 12TBTB, 16TB, 20TB, 24TB |
| SSD (cache) capacities | 0.8TB, 1.6TB, 3.2TB, 7.68TB | 0.8TB, 1.6TB, 3.2TB, 7.68TB |
| Max raw capacity | 1.4PB per chassis | 1.9PB per chassis |
| Front-end network | 10/25/40/100 GigE | 10/25/40/100 GigE |
| Back-end network | 100 GigE, Infiniband | 100 Gb/s Ethernet or Infiniband |
These node hardware attributes, plus a variety of additional info and environmentals, can be easily viewed from the OneFS CLI via the ‘isi_hw_status’ command. For example, from an F710:
# isi_hw_status SerNo: CF25J243000005 Config: 1WVXW ChsSerN: ChsSlot: 2 FamCode: H ChsCode: 4U GenCode: 10 PrfCode: 7 Tier: 3 Class: storage Series: n/a Product: H710-4U-Single-192GB-1x1GE-2x100GE QSFP28-240TB-3277GB SSD-SED HWGen: PSI Chassis: INFINITY (Infinity Chassis) CPU: GenuineIntel (2.00GHz, stepping 0x000806f8) PROC: Single-proc, 16-HT-core RAM: 206152138752 Bytes Mobo: INFINITYPIFANO (Custom EMC Motherboard) NVRam: INFINITY (Infinity Memory Journal) (8192MB card) (size 8589934592B) DskCtl: LSI3808 (LSI 3808 SAS Controller) (8 ports) DskExp: LSISAS35X36I (LSI SAS35x36 SAS Expander - Infinity) PwrSupl: Slot1-PS0 (type=ARTESYN, fw=02.30) PwrSupl: Slot2-PS1 (type=ARTESYN, fw=02.30) NetIF: bge0,lagg0,mce0,mce1,mce2,mce3 BEType: 100GigE FEType: 100GigE LCDver: IsiVFD2 (Isilon VFD V2) Midpln: NONE (No Midplane Support) Power Supplies OK Power Supply Slot1-PS0 good Power Supply Slot2-PS1 good CPU Operation (raw 0x882D0800) = Normal CPU Speed Limit = 100.00% Fan0_Speed = 12000.000 Fan1_Speed = 11880.000 Slot1-PS0_In_Voltage = 208.000 Slot2-PS1_In_Voltage = 207.000 SP_CMD_Vin = 12.100 CMOS_Voltage = 3.080 Slot1-PS0_Input_Power = 280.000 Slot2-PS1_Input_Power = 270.000 Pwr_Consumption = 560.000 SLIC0_Temp = na SLIC1_Temp = na DIMM_Bank0 = 40.000 DIMM_Bank1 = 41.000 CPU0_Temp = -43.000 SP_Temp0 = 37.000 MP_Temp0 = na MP_Temp1 = 29.000 Embed_IO_Temp0 = 48.000 Hottest_SAS_Drv = -26.000 Ambient_Temp = 29.000 Slot1-PS0_Temp0 = 58.000 Slot1-PS0_Temp1 = 38.000 Slot2-PS1_Temp0 = 55.000 Slot2-PS1_Temp1 = 35.000 Battery0_Temp = 36.000 Drive_IO0_Temp = 42.000
Note that the H710 and H7100 are only available in a 384GB memory configuration.
Starting at the business end of the chassis, the articulating front panel display allows the user to join the nodes to a cluster, etc:

The chassis front panel includes an LCD display with 9 cap-touch back-lit buttons. Four LED Light bar segments, 1 per node, illuminate blue to indicate normal operation or yellow to alert of a node fault. The front panel display is hinge mounted so it can be moved clear of the drive sleds, with a ribbon cable running down the length of the chassis to connect the display to the midplane.

As with all PowerScale nodes, the front panel display provides some useful information for the four nodes, such as the ‘outstanding alerts’ status shown above, etc.
For storage, each of the four nodes within a PowerScale H710/0 chassis’ has five associated drive containers, or sleds. These sleds occupy bays in the front of each chassis, with a node’s drive sleds stacked vertically:

Nodes are numbered 1 through 4, left to right looking at the front of the chassis, while the drive sleds are labeled A through E, with sleds A occupying the top row of the chassis.
The drive sled is the tray which slides into the front of the chassis. Within each sled, the 3.5” SAS hard drives it contains are numbered sequentially starting from drive zero, which is the HDD adjacent the airdam.

The H7100 uses a longer 42.2 inch, allowing it to accommodate four HDDs per sled compared to three drives for the H710, which is 36.7 inch in depth. This also means that the H710 can reside in a regular 17” data center rack or cabinet, whereas the H7100 requires a deep rack, such as the Dell Titan cabinet.
The H710 and H7100 platforms support a range of HDD capacities, currently including 2TB, 4, 8, 12, 16, 20, and 24TB capacities, and both regular ISE (instant secure erase) or self-encrypting drive (SED) formats.
Each drive sled has a white ‘not safe to remove’ LED on its front top left, as well as a blue power/activity LED, and an amber fault LED.

The compute modules for each node are housed in the rear of the chassis, and contain CPU, memory, networking, and SSDs, as well as power supplies. Nodes 1 & 2 are a node pair, as are nodes 3 & 4. Each node-pair shares a mirrored journal and two power supplies:

Here’s the detail of an individual compute module, which contains a multi core Sapphire Rapids CPU, memory, M2 flash journal, up to two SSDs for L3 cache, six DIMM channels, front-end 40/100 or 10/25 Gb ethernet, back-end 40/100 or 10/25 Gb ethernet or Infiniband, an ethernet management interface, and power supply and cooling fans:

Of particular note is the ‘journal active’ LED, which is displayed as a white ‘hand icon’. When this is illuminated, it indicates that the mirrored journal is actively vaulting.

Note that a node’s compute module should not be removed from the chassis while this while LED is lit!
On the front of each chassis is an LCD front panel control with back-lit buttons and 4 LED Light Bar Segments – 1 per Node. These LEDs typically display blue for normal operation or yellow to indicate a node fault. This LCD display is hinged so it can be swung clear of the drive sleds for non-disruptive HDD replacement, etc.
Details can be queried with OneFS CLI drive utilities such as ‘isi_radish’ and ‘isi_drivenum’. For example, the command output from an H710 node:
tme-1# isi_drivenum Bay 1 Unit 6 Lnum 15 Active SN:7E30A02K0F43 /dev/da1 Bay 2 Unit N/A Lnum N/A N/A SN:N/A N/A Bay A0 Unit 1 Lnum 12 Active SN:ZRS1HP4G /dev/da4 Bay A1 Unit 17 Lnum 13 Active SN:ZR7105GY /dev/da3 Bay A2 Unit 16 Lnum 14 Active SN:ZRS1HNZG /dev/da2 Bay B0 Unit 24 Lnum 9 Active SN:ZRS1PHFG /dev/da7 Bay B1 Unit 23 Lnum 10 Active SN:ZRS1HEA1 /dev/da6 Bay B2 Unit 22 Lnum 11 Active SN:ZRS1PHFX /dev/da5 Bay C0 Unit 30 Lnum 6 Active SN:ZR5EFV0D /dev/da10 Bay C1 Unit 29 Lnum 7 Active SN:ZR5FE3Z8 /dev/da9 Bay C2 Unit 28 Lnum 8 Active SN:ZR5FE311 /dev/da8 Bay D0 Unit 36 Lnum 3 Active SN:ZR5FE3DA /dev/da13 Bay D1 Unit 35 Lnum 4 Active SN:ZRS1PHEF /dev/da12 Bay D2 Unit 34 Lnum 5 Active SN:ZRS1HP6T /dev/da11 Bay E0 Unit 42 Lnum 0 Active SN:ZRS1PHEM /dev/da16 Bay E1 Unit 41 Lnum 1 Active SN:ZRS1PHDV /dev/da15 Bay E2 Unit 40 Lnum 2 Active SN:ZRS1HPAT /dev/da14
The ‘bay’ locations indicate the drive location in the chassis. ‘Bay 1’ references the cache/metadata SSD, located within the node’s compute module. Whereas the HDDs are referenced by their respective sled (A to E) and drive slot (0 to 2). For example, drive ‘E1’ in the following example:

The H710 and H7100 platforms are available in the following networking configurations, with a 10/25/40/100Gb ethernet front-end and 10/25/40/100Gb ethernet or 100Gb Infiniband back-end:
| Model | H710 | H7100 |
| Front-end network | 10/25/40/100 GigE | 10/25/40/100 GigE |
| Back-end network | 10/25/40/100 GigE, Infiniband | 10/25/40/100 GigE, Infiniband |
These NICs and their PCI bus addresses can be determined via the ’pciconf’ CLI command, as follows:
# pciconf -l | grep mlx mlx4_core0@pci0:59:0:0: class=0x020000 card=0x028815b3 chip=0x100315b3 rev=0x00 hdr=0x00 mlx5_core0@pci0:216:0:0: class=0x020000 card=0x001615b3 chip=0x101515b3 rev=0x00 hdr=0x00 mlx5_core1@pci0:216:0:1: class=0x020000 card=0x001615b3 chip=0x101515b3 rev=0x00 hdr=0x00
Similarly, the NIC hardware details and drive firmware versions can be viewed as follows:
# mlxfwmanager Querying Mellanox devices firmware ... Device #1: ---------- Device Type: ConnectX3 Part Number: 105-001-013-00_Ax Description: Mellanox 40GbE/56G FDR VPI card PSID: EMC0000000004 PCI Device Name: pci0:59:0:0 Port1 MAC: 1c34dae19e31 Port2 MAC: 1c34dae19e32 Versions: Current Available FW 2.42.5000 N/A PXE 3.4.0752 N/A Status: No matching image found Device #2: ---------- Device Type: ConnectX4LX Part Number: 020NJD_0MRT0D_Ax Description: Mellanox 25GBE 2P ConnectX-4 Lx Adapter PSID: DEL2420110034 PCI Device Name: pci0:216:0:0 Base MAC: 1c34da4492e8 Versions: Current Available FW 14.32.2004 N/A PXE 3.6.0502 N/A UEFI 14.25.0018 N/A Status: No matching image found
Compared with their H70x predecessors, the H710 and H7100 see a number of hardware performance upgrades. These include a move to DDR5 memory, Sapphire Rapids CPU, and an upgraded power supply.
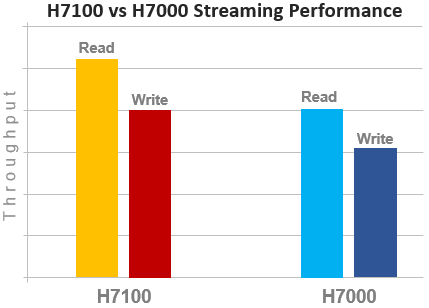
In terms of performance, the new H71x nodes provide a solid improvement over the prior generation. For example, streaming read and writes on both the H7100 and H7000:
OneFS node compatibility provides the ability to have similar node types and generations within the same node pool. In OneFS 9.11 and later, compatibility between the H710 and H7100 nodes and the previous generation platform is supported. Specifically, this node pool compatibility includes:
| PowerScale H-series Node Pool Compatibility | Gen6 | MLK | New |
| H500 | H700 | H710 | |
| H5600 | H7000 | H7100 | |
| H600 | – | – |
Node pool compatibility checking includes drive capacities for both data HDDs and SSD cache. This pool compatibility permits the addition of H710 node pairs to an existing node pool comprising four or more H700s, if desired, rather than creating an entirely new 4-node H710 node pool. Plus, there’s a similar compatibility between the H7100 and H7000 nodes.
Note that, while the H71x is node pool compatible with the H70x, it does require a performance compromise, since the H71x nodes are effectively throttled to match the performance envelope of the H70x nodes.
Apropos storage efficiency, OneFS inline data reduction support on mixed H-series diskpools is as follows:
| Gen6 | MLK | New | Data Reduction Enabled |
| H500 | H700 | H710 | False |
| H500 | – | H710 | False |
| – | H700 | H710 | True |
| H5600 | H7000 | H7100 | True |
| H5600 | – | H7100 | True |
| – | H7000 | H7100 | True |
In the next article in this series, we’ll turn our attention to the PowerScale A310 and A3100 platforms.