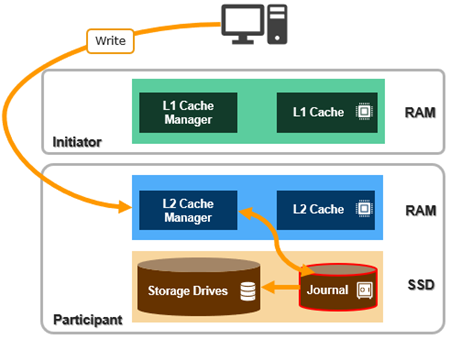
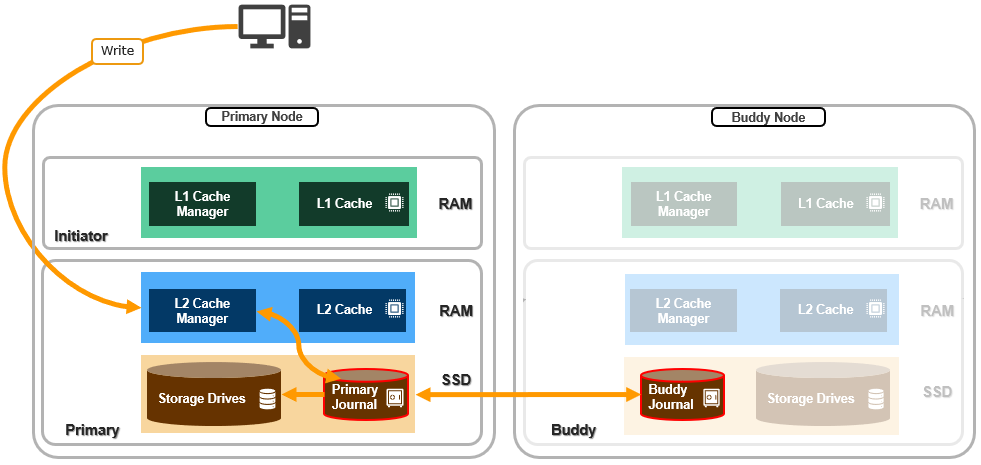
In addition to a variety of software features, OneFS 9.11 also introduces support for a new PowerScale performance accelerator node, based upon the venerable 1RU Dell PE R660 platform.
The diskless PA110 accelerator can simply, and cost effectively, augment the CPU, RAM, and bandwidth of a network or compute-bound cluster without significantly increasing its capacity or footprint.

Since the accelerator node contains no storage and a sizable RAM footprint, it has a substantial L1 cache, since all the data is fetched from other storage nodes. Cache aging is based on a least recently used (LRU) eviction policy and the PA110 is available in a single memory configuration, with 512GB of DDR5 DRAM per node. The PA110 also supports both inline compression and deduplication.
In particular, the PA110 accelerator can provide significant benefit to serialized, read-heavy, streaming workloads by virtue of its substantial, low-churn L1 cache, helping to increase throughput and reduce latency. For example, a typical scenario for PA110 addition could be a small all-flash cluster supporting a video editing workflow that is looking for a performance and/or front-end connectivity enhancement, but no additional capacity.
Other than a low capacity M.2 SSD boot card, the PA110 node contains no local storage or journal. This new accelerator is fully compatible with clusters containing the current and previous generation PowerScale nodes. Also, unlike storage nodes which require the addition of a 3 or 4 node pool of similar nodes, a single PA110 can be added to a cluster. The PA110 can be added to a cluster containing all-flash, hybrid, and archive nodes.
Under the top cover, the one rack-unit PA110 enclosure contains dual Sapphire Rapids 6442Y CPUs with 24 core/48 thread-60MB L3, running at 2.6GHz. This is complemented by 512GB of DDR5 memory and dual 960GB M.2 mirrored boot media.

Networking comprises the venerable Mellanox CX6 series NICs, with options including CX6-LX Dual port 25G, CX6-DX Dual port 100G, or MLX CX6 VPI 200G Ethernet.

The PA110 also includes a LOM (Lan-On-Motherboard) port for management and a RIO/DB9 for the serial port. This is all powered by dual 1100W Titanium hot swappable power supplies.
The PowerScale PA110 also uses a new boot-optimized storage solution (BOSS) for its boot media. This comprises a BOSS module and associated card carrier. The module is housed in the chassis as shown:

The card carrier holds two M.2 NVMe SSD cards, which can be removed from the rear of the node as follows:

Note that, unlike PowerScale storage nodes, since the accelerator does not provide any /ifs filesystem storage capacity, the PowerScale PA110 node does not require OneFS feature licenses for any of the various data services running in a cluster.
The PowerScale PA110 can also be configured to order in ‘backup mode’, too. In this configuration, the accelerator also includes a pair of fibre channel ports, provided by an Emulex LPE35002 32Gb FC HBA. This enables direct, or two-way, NDMP backup from a cluster to a tape library or VTL, either directly attached or across a fibre channel fabric.

With a fibre channel card installed in slot 2, the PA110 backup accelerator integrates seamlessly with current DR infrastructure, as well as with leading data backup and recovery software technologies to satisfy the availability and recovery SLA requirements of a wide variety of workloads.

As a backup accelerator, the PA110 aids overall cluster performance by offloading NDMP backup traffic directly to the fibre channel ports and reducing CPU and memory consumption on storage nodes – thereby minimizing impact on front end workloads. This can be of particular benefit to clusters that have been using chassis-based nodes populated with fibre channel cards. In these cases, a simple, non-disruptive addition of PA110 backup accelerator node(s) frees up compute resources on the storage nodes, boosting client workload performance and shrinking NDMP backup windows.
The following table includes the hardware specs for the new PowerScale PA110 performance accelerator, as compared to its predecessors (P100 and B100), which are as follows:
| Component (per node) | PA110 (New( | P100 (Prior gen) | B100 (Prior gen) |
| OneFS release | OneFS 9.11 or later | OneFS 9.3 or later | OneFS 9.3 or later |
| Chassis | PowerEdge R660 | PowerEdge R640 | PowerEdge R640 |
| CPU | 24 cores (dual socket Intel 6442Y @ 2.6Ghz) | 20 cores (dual socket Intel 4210R @ 2.4Ghz) | 20 cores (dual socket Intel 4210R @ 2.4Ghz) |
| Memory | 512GB DDR5 | 384GB or 768GB DDR4 | 384GB DDR4 |
| Front-end I/O | 2 x 10/25 Gb Ethernet; Or
2 x 40/100Gb Ethernet; Or 2 x HDR Infiniband (200Gb) |
2 x 10/25 Gb Ethernet Or
2 x 40/100Gb Ethernet |
2 x 10/25 Gb Ethernet Or
2 x 40/100Gb Ethernet |
| Back-end I/O | 2 x 10/25 Gb Ethernet Or
2 x 40/100Gb Ethernet Or 2 x HDR Infiniband (200Gb) Optional 2 x FC for NDMP |
2 x 10/25 Gb Ethernet Or
2 x 40/100Gb Ethernet Or 2 x QDR Infiniband |
2 x 10/25 Gb Ethernet Or
2 x 40/100Gb Ethernet Or 2 x QDR Infiniband |
| Mgmt Port | LAN on motherboard | 4 x 1GbE (rNDC) | 4 x 1GbE (rNDC) |
| Journal | N/A | N/A | N/A |
| Boot media | BOSS module 960GB | 2x 960GB SAS SSD drives | 2x 960GB SAS SSD drives |
| IDSDM | 1 x 32GB microSD (Receipt and recovery boot image) | 1x 32GB microSD (Receipt and recovery boot image) | 1x32GB microSD (Receipt and recovery boot image) |
| Power Supply | Dual redundant 1100W
100-240V, 50/60Hz |
Dual redundant 750W 100-240V, 50/60Hz | Dual redundant 750W 100-240V, 50/60Hz |
| Rack footprint | 1RU | 1RU | 1RU |
| Cluster addition | Minimum one node, and single node increments | Minimum one node, and single node increments | Minimum one node, and single node increments |
These node hardware attributes can be easily viewed from the OneFS CLI via the ‘isi_hw_status’ command.