To complement the actual SmartDedupe job, a dry-run Dedupe Assessment job is also provided to help estimate the amount of space savings that will be seen by running deduplication on a particular directory or set of directories. The dedupe assessment job reports a total potential space savings. The dedupe assessment does not differentiate the case of a fresh run from the case where a previous dedupe job has already done some sharing on the files in that directory. The assessment job does not provide the incremental differences between instances of this job. Isilon recommends that the user should run the assessment job once on a specific directory prior to starting an actual dedupe job on that directory.
The assessment job runs similarly to the actual dedupe job, but uses a separate configuration. It also does not require a product license and can be run prior to purchasing SmartDedupe in order to determine whether deduplication is appropriate for a particular data set or environment. This can be configured from the WebUI by browsing to File System > Deduplication > Settings and adding the desired directories(s) in the ‘Assess Deduplication’ section.
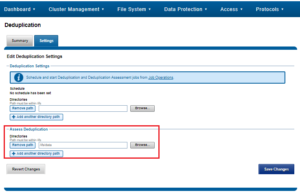
Alternatively, the following CLI syntax will achieve the same result:
# isi dedupe settings modify –add-assess-paths /ifs/data
Once the assessment paths are configured, the job can be run from either the CLI or WebUI. For example:
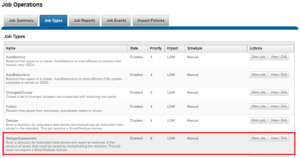
Or, from the CLI:
# isi job types list | grep –I assess DedupeAssessment Yes LOW # isi job jobs start DedupeAssessment Once the job is running, it’s progress and be viewed by first listing the job to determine it’s job ID. # isi job jobs list ID Type State Impact Pri Phase Running Time --------------------------------------------------------------- 919 DedupeAssessment Running Low 6 1/1 - --------------------------------------------------------------- Total: 1 And then viewing the job ID as follows: # isi job jobs view 919 ID: 919 Type: DedupeAssessment State: Running Impact: Low Policy: LOW Pri: 6 Phase: 1/1 Start Time: 2019-01-21T21:59:26 Running Time: 35s Participants: 1, 2, 3 Progress: Iteration 1, scanning files, scanned 61 files, 9 directories, 4343277 blocks, skipped 304 files, sampled 271976 blocks, deduped 0 blocks, with 0 errors and 0 unsuccessful dedupe attempts Waiting on job ID: - Description: /ifs/data
The running job can also be controlled and monitored from the WebUI:
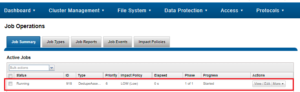
Under the hood, the dedupe assessment job uses a separate index table from the actual dedupe process. Plus, for the sake of efficiency, the assessment job also samples fewer candidate blocks than the main dedupe job, and obviously does not actually perform deduplication. This means that, often, the assessment will provide a slightly conservative estimate of the actually deduplication efficiency that’s likely to be achieved.
Using the sampling and consolidation statistics, the assessment job provides a report which estimates the total dedupe space savings in bytes. This can be viewed for the CLI using the following syntax:
# isi dedupe reports view 919
Time: 2020-09-21T22:02:18
Job ID: 919
Job Type: DedupeAssessment
Reports
Time: 2020-09-21T22:02:18
Results:
Dedupe job report:{
Start time = 2020-Sep-21:21:59:26
End time = 2020-Sep-21:22:02:15
Iteration count = 2
Scanned blocks = 9567123
Sampled blocks = 383998
Deduped blocks = 2662717
Dedupe percent = 27.832
Created dedupe requests = 134004
Successful dedupe requests = 134004
Unsuccessful dedupe requests = 0
Skipped files = 328
Index entries = 249992
Index lookup attempts = 249993
Index lookup hits = 1
}
Elapsed time: 169 seconds
Aborts: 0
Errors: 0
Scanned files: 69
Directories: 12
1 path:
/ifs/data
CPU usage: max 81% (dev 1), min 0% (dev 2), avg 17%
Virtual memory size: max 341652K (dev 1), min 297968K (dev 2), avg 312344K
Resident memory size: max 45552K (dev 1), min 21932K (dev 3), avg 27519K
Read: 0 ops, 0 bytes (0.0M)
Write: 4006510 ops, 32752225280 bytes (31235.0M)
Other jobs read: 0 ops, 0 bytes (0.0M)
Other jobs write: 41325 ops, 199626240 bytes (190.4M)
Non-JE read: 1 ops, 8192 bytes (0.0M)
Non-JE write: 22175 ops, 174069760 bytes (166.0M)
Or from the WebUI, by browsing to Cluster Management > Job Operations > Job Types:
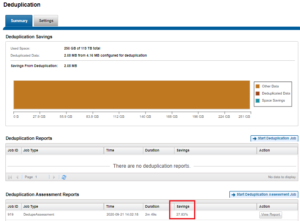
As indicated, the assessment report for job # 919 in this case discovered the potential of 27.8% in data savings from deduplication.
Note that the SmartDedupe dry-run estimation job can be run without any licensing requirements, allowing an assessment of the potential space savings that a dataset might yield before making the decision to purchase the full product.