Software journal mirroring (SJM) in OneFS 9.11 delivers critical file system support to meet the reliability requirements for PowerScale platforms with high capacity flash drives. By keeping a synchronized and consistent copy of the journal on another node, and automatically recovering the journal from it upon failure, enabling SJM can reduce the node failure rate by around three orders of magnitude – while also boosting storage efficiency by negating the need for a higher level of on-disk FEC protection.
SJM is enabled by default for the applicable platforms on new clusters. So for clusters including F710 or F910 nodes with large QLC drives that ship with 9.11 installed, SJM will be automatically activated.
SJM adds a mirroring scheme, which provides the redundancy for the journal’s contents.
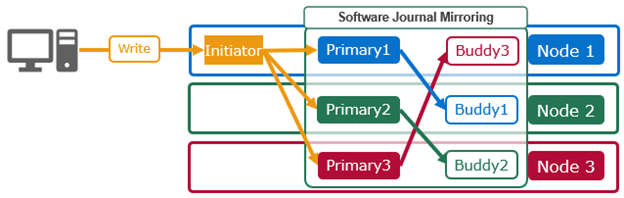
This is where /ifs updates are sent to a node’s local, or primary, journal as usual. But they’re also synchronously replicated, or mirrored, to another node’s journal, too – referred to as the ‘buddy’.
Every node in an SJM-enabled pool is dynamically assigned a buddy node, and if a new SJM-capable node is added to the cluster, it’s automatically paired up with a buddy. These buddies are unique for every node in the cluster.
SJM’s automatic recovery scheme can use a buddy journal’s contents to re-form the primary node’s journal. And this recovery mechanism can also be applied manually if a journal device needs to be physically replaced.
The introduction of SJM changes the node recovery options slightly in OneFS 9.11. These options now include an additional method for restoring the journal:

This means that if a node within an SJM-enabled pool ends up at the ‘stop_boot’ prompt, before falling back to SmartFail, the available options in order of desirability are:
| Order | Options | Description |
| 1 | Automatic journal recovery | OneFS will first try to automatically recover from the local copy.
|
| 2 | Automatic journal mirror recovery | Automatic journal mirror recovery attempts to SyncBack from the buddy node’s journal. |
| 3 | Manual SJM recovery | Dell support can attempt a manual SJM recovery, particularly in scenarios where a bug or issue in the software journal mirroring feature itself is inhibiting automatic recovery in some way. |
| 4 | SmartFail | OneFS quarantines the node, places it into a read-only state, and reprotects by distributing the data to other devices. |
While SJM is available upon upgrade commit to OneFS 9.11, it is not automatically activated. So any F710 or F910 SJM-capable node pools that were originally shipped with OneFS 9.10 installed will require SJM to be manually enabled after their upgrade to 9.11.
If SJM is not activated on a cluster with capable node pools running OneFS 9.11, a CELOG alert will be raised, encouraging the customer to enable it. This CELOG alert will contain information about the administrative actions required to enable SJM. Additionally, a pre-upgrade check is also included in OneFS 9.11 to prevent any existing cluster with nodes containing 61TB drives that were shipped with OneFS 9.9 or older installed, from upgrading directly to 9.11 until the afflicted nodes have been USB-reimaged and their journals reformatted.
For SJM-capable clusters which do not have journal mirroring enabled, the CLI command (and platform API endpoint) to activate SJM operate at the nodepool level. Each SJM-capable pool will need to be enabled separately via the ‘isi storagepool nodepools modify’ CLI command, plus the pool name and the new ‘–sjm-enable=true’ argument.
# isi storagepool nodepools modify <name> --sjm-enabled true
Note that this new syntax is only applicable only for nodepool(s) with SJM-capable nodes.
Similarly, to query the SJM status on a cluster’s nodepools:
# isi storagepool nodepools list –v | grep –e ‘SJM’ –e ‘Name:’
And to check a cluster’s nodes for SJM capabilities:
# isi storagepool nodetypes list -v | grep -e 'Product' -e 'Capable'
So there are a couple of considerations with SJM that should be borne in mind. As mentioned previously, any SJM-capable nodes that are upgraded from OneFS 9.10 will not have SJM enabled by default. So if, after upgrade to 9.11, a capable pool remains in an SJM-disabled state, a CELOG warning will be raised informing that the data may be under-protected, and hence it’s reliability lessened. And the CELOG event will include recommended corrective and remedial action. So administrative intervention will be required to enable SJM on this particular node pool, ideally, or alternatively increase the protection level to meet the same reliability goal.
So how impactful is SJM to protection overhead on an SJM-capable node pool/cluster? The following table shows the protection layout, both with and without SJM, for the F710 and F910 nodes containing 61TB drives:
| Node type | Drive Size | Journal | Mirroring | +d2:1n | +3d:1n1d | +2n | +3n |
| F710 | 61TB | SDPM | 3 | 4-6 | 7-34 | 35-252 | |
| F710 | 61TB | SDPM | SJM | 4-16 | 17-252 | ||
| F910 | 61TB | SDPM | 3 | 5-19 | 20-252 | ||
| F910 | 61TB | SDPM | SJM | 3-16 | 17-252 |
Taking the F710 with 61TB drives example above, without SJM +3n protection is required at 35 nodes and above. In contrast, with SJM-enabled, the +3d:1n1d protection level suffices all the way up to the current maximum cluster size of 252 nodes.
Generally, beyond enabling it on any capable-pools, after upgrading to 9.11 SJM just does its thing and does not require active administration or management. However, with a corresponding buddy journal for every primary node, there may be times when a primary and its buddy become un-synchronized. Clearly, this would mean that mirroring is not functioning correctly and a SyncBack recovery attempt would be unsuccessful. OneFS closely monitors this scenario, and will fire either of the top two CELOG event types below to alert the cluster admin in the event that journal syncing and/or mirroring are not working properly:
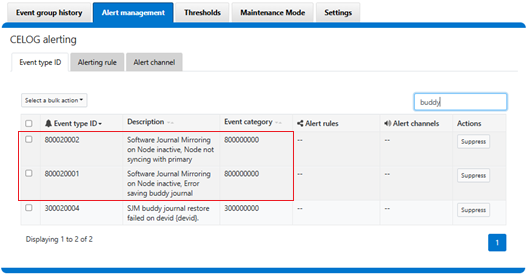
Possible causes for this could include the buddy remaining disconnected, or in a read-only state, for a protracted period of time. Or a software bug or issue, that’s preventing successful mirroring. This would result in a CELOG warning being raised for the buddy of the specific node, with the suggested administrative action included in the event contents.
Also, be aware that SJM-capable and non-SJM-capable nodes can be placed in the same nodepool if needed, but only if SJM is disabled on that pool – and the protection increased correspondingly.
The following chart illustrates the overall operational flow of SJM:
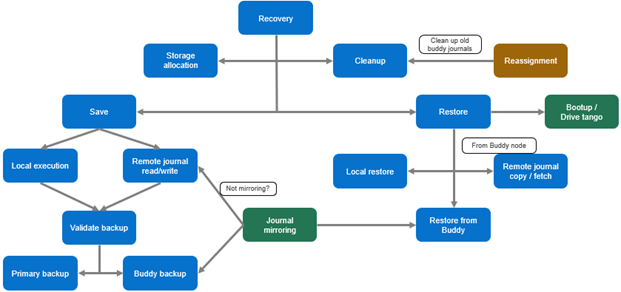
SJM is a core file system feature, so the bulk of its errors and status changes are written to the ubiquitous /var/log/messages file. However, since the Buddy assignment mechanism is a separate component with its own user-space demon, its notifications and errors are sent to a dedicated ‘isi_sjm_budassign_d’ log. This logfile is located at:
/var/log/isi_sjm_budassign_d.log