As we saw in the previous article, when data is written to the cluster, SmartPools determines which pool to write to based upon either path or on any other criteria.
If a file matches a file pool policy which is based on any other criteria besides path name, SmartPools will write that file to the Node Pool with the most available capacity.
However, if a file matches a file pool policy based on directory path, that file will be written into the Node Pool dictated by the File Pool policy immediately.

If the file matches a file pool policy that places it on a different Node Pool than the highest capacity Node Pool, it will be moved when the next scheduled SmartPools job runs.
If a filepool policy applies to a directory, any new files written to it will automatically inherit the settings from the parent directory. Typically, there is not much variance between the directory and the new file. So, assuming the settings are correct, the file is written straight to the desired pool or tier, with the appropriate protection, etc. This applies to access protocols like NFS and SMB, as well as copy commands like ‘cp’ issued directly from the OneFS command line interface (CLI). However, if the file settings differ from the parent directory, the SmartPools job will correct them and restripe the file. This will happen when the job next runs, rather than at the time of file creation.
However, simply moving a file into the directory (via the UNIX CLI commands such as cp, mv, etc) will not occur until a SmartPools, SetProtectPlus, Multiscan, or Autobalance job runs to completion. Since these jobs can each perform a re-layout of data, this is when the files will be re-assigned to the desired pool. The file movement can be verified by running the following command from the OneFS CLI:
# isi get -dD <dir>
So the key is whether you’re doing a copy (that is, a new write) or not. As long as you’re doing writes and the parent directory of the destination has the appropriate file pool policy applied, you should get the behavior you want.
One thing to note: If the actual operation that is desired is really a move rather than a copy, it may be faster to change the file pool policy and then do a recursive “isi filepool apply –recurse” on the affected files.
There’s negligible difference between using an NFS or SMB client versus performing the copy on-cluster via the OneFS CLI. As mentioned above, using isi filepool apply will be slightly quicker than a straight copy and delete, since the copy is parallelized above the filesystem layer.
A file pool policy may be crafted which dictates that anything written to path /ifs/path1 is automatically moved directly to the Archive tier. This can easily be configured from the OneFS WebUI by navigating to File System > Storage Pools > File Pool Policies:
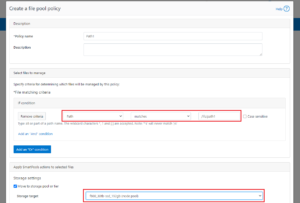
In the example above, a path based policy is created such that data written to /ifs/path1 will automatically be placed on the cluster’s F600 node pool.
For file Pool Policies that dictate placement of data based on its path, data typically lands on the correct node pool or tier without a SmartPools job running. File Pool Policies that dictate placement of data on other attributes besides path name get written to Disk Pool with the highest available capacity and then moved, if necessary to match a File Pool policy, when the next SmartPools job runs. This ensures that write performance is not sacrificed for initial data placement.
Any data not covered by a File Pool policy is moved to a tier that can be selected as a default for exactly this purpose. If no Disk Pool has been selected for this purpose, SmartPools will default to the Node Pool with the most available capacity.
Be aware that, when reconfiguring an existing path-based filepool policy to target a different nodepool or tier, the change will not immediately take effect for the new incoming data. The directory where new files will be created must be updated first and there are a several options available to address this:
- Running the SmartPools job will achieve this. However, this can take a significant amount of time, as the job may entail restriping or migrating a large quantity of file data.
- Invoking the ’isi filepool apply <path>’ command on a single directory in question will do it very rapidly. This option is ideal for a single, or small number, of ‘incoming’ data directories.
- To update all directories in a given subtree, but not affect the files’ actual data layouts, use:
# isi filepool apply --dont-restripe --recurse /ifs/path1
- OneFS also contains the SmartPoolsTree job engine job specifically for this purpose. This can be invoked as follows:
# isi job start SmartPoolsTree --directory-only --path /ifs/path1
For example, a cluster has both an F600 pool and an A2000 pool. A directory (/ifs/path1) is created and a file (file1.txt) written to it:
# mkdir /ifs/path1 # cd !$; touch file1.txt
As we can see, this file is written to the default A2000 pool:
# isi get -DD /ifs/path1/file1.txt | grep -i pool * Disk pools: policy any pool group ID -> data target a2000_200tb_800gb-ssd_16gb:97(97), metadata target a2000_200tb_800gb-ssd_16gb:97(97)
Next, a path-based file pool policy is created such that files written to /ifs/test1 are automatically directed to the cluster’s F600 tier:
# isi filepool policies create test2 --begin-filter --path=/ifs/test1 --and --data-storage-target f600_30tb-ssd_192gb --end-filter
# isi filepool policies list Name Description CloudPools State ------------------------------------ Path1 No access ------------------------------------ Total: 1
# isi filepool policies view Path1 Name: Path1 Description: CloudPools State: No access CloudPools Details: Policy has no CloudPools actions Apply Order: 1 File Matching Pattern: Path == path1 (begins with) Set Requested Protection: - Data Access Pattern: - Enable Coalescer: - Enable Packing: - Data Storage Target: f600_30tb-ssd_192gb Data SSD Strategy: metadata Snapshot Storage Target: - Snapshot SSD Strategy: - Cloud Pool: - Cloud Compression Enabled: - Cloud Encryption Enabled: - Cloud Data Retention: - Cloud Incremental Backup Retention: - Cloud Full Backup Retention: - Cloud Accessibility: - Cloud Read Ahead: - Cloud Cache Expiration: - Cloud Writeback Frequency: - ID: Path1
The ‘isi filepool apply’ command is run on /ifs/path1 in order to activate the path-based file policy:
# isi filepool apply /ifs/path1
A file (file-new1.txt) is then created under /ifs/path1:
# touch /ifs/path1/file-new1.txt
An inspection shows that this file is written to the F600 pool, as expected per the Path1 file pool policy:
# isi get -DD /ifs/path1/file-new1.txt | grep -i pool * Disk pools: policy f600_30tb-ssd_192gb(9) -> data target f600_30tb-ssd_192gb:10(10), metadata target f600_30tb-ssd_192gb:10(10)
The legacy file (/ifs/path1/file1.txt) is still on the A2000 pool, despite the path-based policy. However, this policy can be enacted on pre-existing data by running the following:
# isi filepool apply --dont-restripe --recurse /ifs/path1
Now, the legacy files are also housed on the F600 pool, and any new writes to the /ifs/path1 directory will also be written to the F600s:
# isi get -DD file1.txt | grep -i pool * Disk pools: policy f600_30tb-ssd_192gb(9) -> data target a2000_200tb_800gb-ssd_16gb:97(97), metadata target a2000_200tb_800gb-ssd_16gb:97(97)