OneFS currently supports a maximum cluster size of 252 nodes, up from 144 nodes in releases prior to OneFS 8.2. To support this increase in scale, GMP transaction latency was dramatically improved by eliminating serialization and reducing its reliance on exclusive merge locks.
Instead, GMP now employs a shared merge locking model.
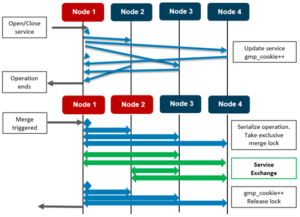
Take the four node cluster above. In this serialized locking example, the interaction between the two operations is condensed, illustrating how each node can finish its operation independent of its peers. Note that the diamond icons represent the ‘loopback’ messaging to node 1.
Each node takes its local exclusive merge lock. By not serializing/locking, the group change impact is significantly reduced, allowing OneFS to support greater node counts. It is expensive to stop GMP messaging on all nodes to allow this. While state is not synchronized immediately, it will be the same after a short while. The caller of a service change will not return until all nodes have been updated. Once all nodes have replied, the service change has completed. It is possible that multiple nodes change a service at the same time, or that multiple services on the same node change.
The example above illustrates nodes {1,2} merging with nodes {3, 4}. The operation is serialized, and the exclusive merge lock will be taken. In the diagram, the wide arrows represent multiple messages being exchanged. The green arrows show the new service exchange. Each node sends its service state to all the nodes new to it and receives the state from all new nodes. There is no need to send the current service state to any node in a group prior to the merge.
During a node split, there are no synchronization issues because either order results in the services being down, and the existing OneFS algorithm still applies.
OneFS 8.2 also saw the introduction of a new daemon, isi_array_d, which replaces isi_boot_d from prior versions. Isi_array_d is based on the Paxos consensus protocol.
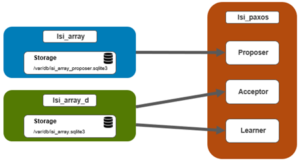
Paxos is used to manage the process of agreeing on a single, cluster-wide result amongst a group of potential transient nodes. Although no deterministic, fault-tolerant consensus protocol can guarantee progress in an asynchronous network, Paxos guarantees safety (consistency), and the conditions that could prevent it from making progress are difficult to trigger.
In 8.2 and later, a unique GMP Cookie on each node in the cluster replaces the previous cluster-wide GMP ID. For example
- # sysctl efs.gmp.group
- gmp.group: <889a5e> (5) :{ 1-3:0-5, smb: 1-3, nfs: 1-3, all_enabled_protocols: 1-3, isi_cbind_d: 1-3 }
The GMP Cookie is a hexadecimal number. The initial value is calculated as a function of the current time, so it remains unique even after a node is rebooted. The cookie changes whenever there is a GMP event and is unique on power-up. In this instance, the (5) represents the configuration generation number.
In the interest of ease of readability in large clusters, logging verbosity is also reduced. Take the following syslog entry, for example:
2019-05-12T15:27:40-07:00 <0.5> (id1) /boot/kernel.amd64/kernel: connects: { { 1.7.135.(65-67)=>1-3 (IP), 0.0.0.0=>1-3, 0.0.0.0=>1-3, }, cfg_gen:1=>1-3, owv:{ build_version=0x0802009000000478 overrides=[ { version=0x08020000 bitmask=0x0000ae1d7fffffff }, { version=0x09000100 bitmask=0x0000000000004151 } ] }=>1-3, }
Only the lowest node number in a group proposes a merge or split to avoid too many retries from multiple proposing nodes.
GMP will always select nodes to merge to form the biggest group and equal size groups will be weighted towards the smaller node numbers. For example:
{1, 2, 3, 5} > {1, 2, 4, 5}
Discerning readers will have likely noticed a new ‘isi_cbind_d’ entry appended to the group sysctl output above. This new GMP service shows which nodes have connectivity to the DNS servers. For instance, in the following example node 2 is not communicating with DNS.
# sysctl efs.gmp.group
efs.gmp.group: <889a65> (5) :{ 1-3:0-5, smb: 1-3, nfs: 1-3, all_enabled_protocols: 1-3, isi_cbind_d: 1,3 }
As you may recall, isi_cbind_d is the distributed DNS cache daemon in OneFS. The primary purpose of cbind is to accelerate DNS lookups on the cluster, in particular for NFS, which can involve a large number of DNS lookups, especially when netgroups are used. The design of the cache is to distribute the cache and DNS workload among each node of the cluster.
Cbind has also also re-architected to improve its operation with large clusters. The primary change has been the introduction of a consistent hash to determine the gateway node to cache a request. This consistent hashing algorithm, which decides on which node to cache an entry, has been designed to minimize the number of entry transfers as nodes are added/removed. In so doing, it has also usefully reduced the number of threads and UDP ports used.
The cache is logically divided into two parts:
| Component | Description |
| Gateway cache | The entries that this node will refresh from the DNS server. |
| Local cache | The entries that this node will refresh from the Gateway node. |
To illustrate cbind consistant hashing, consider the following three node cluster:
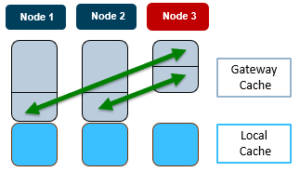
In the scenario above, when the cbind service on Node 3 becomes active, one third each of the gateway cache from node 1 and 2 respectively gets transferred to node 3.
Similarly, if node 3’s cbind service goes down, it’s gateway cache is divided equally between nodes 1 and 2.
For a DNS request on node 3, the node first checks its local cache. If the entry is not found, it will automatically query the gateway (for example, node 2). This means that even if node 3 cannot talk to the DNS server directly, it can still cache the entries from a different node.