As we saw in the previous blog in this series, with the inclusion of Google Cloud (GCP) in OneFS 9.7, SmartSync Cloud Copy now supports all three of the principal public cloud hyperscalers.
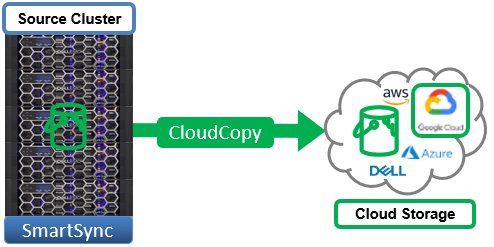
Object data replication to Google Cloud (GCP) can be configured in OneFS 9.7 via the ‘isi dm accounts create’ CLI command. Required information includes the regular account configuration parameters plus the following GCP-specific settings:
- GCP account type
- GCP URI
- Access ID
- Secret key
Or, more specifically:
| Parameter | Description |
| Object store type | GCP (or AWS_S3, Azure, ECS_S3, etc) |
| URI | {http,https}://hostname:port/bucketname |
| Auth | Access ID, Secret Key |
| Proxy | Optional proxy information |
For example:
# isi dm account create --account-type GCP --name [Account Name] --access-id [GCP access-id] --uri [GCP URI with bucket-name] --auth-mode CLOUD --secret-key [GCP secret-key]
Once created, the new account can be verified with the following command:
# isi dm accounts list
Additionally, the next steps for SmartSync configuration and policy creation are covered in detail in the following blog article.
SmartSync Cloud Copy supports both push and pull replication, permitting the same dataset that is copied to GCP with a push to be copied back to the cluster via a corresponding pull.
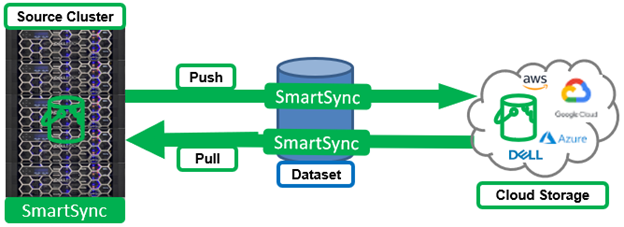
Be aware that a dataset must be available before a policy runs, or the policy will fail.
Also note that, while multiple GCP URIs and credentials are supported by SmartSync, they are not supported on the same account. Multiple accounts and multiple corresponding policies would need to be created for SmartSync.
Other SmartSync features and functionality includes:
| Feature | Details |
| Bandwidth throttling | Set of netmask rules. Limits are per-node. |
| CPU throttling | Allowed and Back-off CPU percentages. |
| Base policies | Template providing common values to groups of related policies (schedule, source base path, enable/disable, etc). Ie. Disabling base policy affects all linked concrete policies. |
| Concrete policy | Predefined set of fields from the base policy |
| Unconnected nodes (NANON) | Active accounts are monitored by each node. No work allocation to nodes without network access. |
| Snapshot locking | Avoids accidental snapshot deletion, with subsequent re-base-lining. |
Behind the scenes, dataset creation leverages a SnapshotIQ snapshot, which can be inspected via the ‘isi snapshot list’ command. These DM dataset snapshots are easily recognizable due to their ‘isi_dm’ prefixed naming convention.
The SmartSync Cloud Copy format provides both regular file representation, browsability and usability of file system data in the cloud. In addition to the replication of the actual data, SmartSync also preserves the common file attributes including Windows ACLs, POSIX permissions and attributes, creation times, extended attributes, etc. However, there are certain considerations and limitations to be aware of, such as no incremental copy. These also include:
| CloudCopy Caveats | Details |
| ADS files | Skipped when encountered. |
| Hardlinks | An object will be created for each link (ie. links are not preserved). |
| Symlinks | Skipped when encountered. |
| Directories | An object is created for each directory. |
| Special files | Skipped when encountered. |
| Metadata | Only POSIX mode bits, UID, GID, atime, mtime, ctime are preserved. |
| Filename encodings | Converted to UTF-8. |
| Path | Path relative to root copy directory is used as object key. |
| Large files | An error is returned for files larger than the cloud providers maximum object size. |
| Long filenames | File names exceeding 256 bytes are compressed. |
| Long paths | Junction points are created when paths exceed 1024 bytes to redirect where objects are being stored |
| Sparse files | Sparse sections are not preserved and are written out fully as zeros. |
SmartSync allows subsequent incremental data movement by managing and re-transferring failed file transfers. Similarly, Dataset reconnect enables systems with common base datasets to establish instant incremental syncs. SmartSync also proactively locks the SnapshotIQ snapshots it uses, providing better separation between Datamover and other snapshots.
Performance-wise, SmartSync is powered by a scalable run-time engine, spanning the cluster, and which spins up threads (fibers) on demand and uses asynchronous IO to process replication tasks (chunks). Batch operations are used for efficient small file, attribute, and data block transfer. Namespace contention avoidance, efficient snapshot utilization, and separation of dataset creation from transfer are salient design features of the both the baseline and incremental sync algorithms.