There have been several recent enquires about large scale file deletes, so a quick article on this topic seemed appropriate.
For example, imagine a workflow that involves creating and deleting thousands or millions of files of varying sizes each day. The serial deletion of these files at the NFS and SMB host level would be incredibly slow and inefficient. Fortunately, OneFS has a purpose-built tool for this: the TreeDelete job.
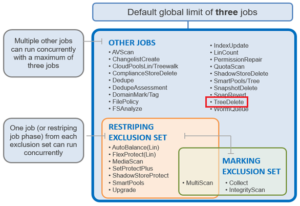
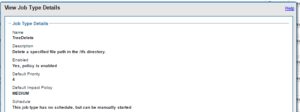
Within the OneFS Job Engine, TreeDelete is a single phase job which runs by default with ‘medium’ impact and a default priority value of 4.
The command line syntax to kick off an instance of this job is:
# isi job jobs start treedelete –-paths <path>
Or, alternatively, via the platform API:
# curl -k -u username:password -H 'Content-Type: application/json' --request POST --data '{"paths": ["<path>"], "type": "treedelete", "allow_dup": true}' 'https://<cluster_IP>:8080/platform/1/job/jobs'
Note that the ‘path’ argument for these commands must be within the cluster’s /ifs partition. TreeDelete will not work on any of the other OneFS filesystem partitions, such as /root, /var, etc, which will fail with “non-valid partition” error. Also, if attempting to delete /ifs/.ifsvar, the TreeDelete job will fail with “Invalid path specified”. Beyond these however, TreeDelete does not prompt to ensure that you’ve selected the desired directory path to remove, etc. So, to avoid any unpleasant surprises, check twice before running the TreeDelete job to ensure that you have configured the job correctly and specified the correct path(s): There is no ‘undo’ button.
Multiple directory paths can be specified as part of this command. For example:
# isi job jobs start treedelete --paths /ifs/dir1 --paths /ifs/dir2 --paths /ifs/dir3 –paths /ifs/dir4
Deleting more than 60 paths in a single TreeDelete job command has been successful. And you’ll likely hit the command line max length well before finding a tree delete path limit. Additionally, you can always queue up to thirty TreeDelete jobs, if desired.
TreeDelete job progress is reported a percentage in “isi stat” output:
TreeDelete (12) MEDIUM 02/16 11:34 00:01:11 24% /ifs/data/recycle
Upon completion, the job status will be reported as such:
Fri Mar 5 23:19:26 2021 Daemon[57225]: TreeDelete job deleted 131028 files/dirs, 322GB, with 0 errors
Plus, a full job report, containing deleted data counts and capacities, cluster resource utilization, and job engine stats, etc, is available as follows:
# isi job reports view 12 -v
TreeDelete[12] phase 1 (2021-03-05T23:19:26)
--------------------------------------------
Paths [ "/ifs/data/trash" ]
Files 131028
Directories 101
Apparent size 267387005115
Physical size 357773443072
JE/Coordinator/Merge microseconds { sum = 55, mean = 11, stdev = 8.12404 }
JE/Error Count 0
JE/Group at phase end [ "<1,8> :{ 1-4:0-14, smb: 1-4, nfs: 1-4, swift: 1-4, all_enabled_protocols: 1-4, isi_cbind_d: 1-4, lsass: 1-4, s3: 1-4 }" ]
JE/Manager/Merge microseconds { sum = 150, mean = 5.17241, stdev = 2.76766 }
JE/Stats/CPU avg 13.73%
JE/Stats/CPU max 506.84%
JE/Stats/CPU max node 1
JE/Stats/CPU min 0.00%
JE/Stats/CPU min node 2
JE/Stats/IO/Current job/Read bytes 0 bytes
JE/Stats/IO/Current job/Reads 0
JE/Stats/IO/Current job/Write bytes 741941248 bytes (707.57M)
JE/Stats/IO/Current job/Writes 90569
JE/Stats/IO/Non-JE/Read bytes 0 bytes
JE/Stats/IO/Non-JE/Reads 0
JE/Stats/IO/Non-JE/Write bytes 26492928 bytes (25.27M)
JE/Stats/IO/Non-JE/Writes 3234
JE/Stats/IO/Other jobs/Read bytes 0 bytes
JE/Stats/IO/Other jobs/Reads 0
JE/Stats/IO/Other jobs/Write bytes 36274176 bytes (34.59M)
JE/Stats/IO/Other jobs/Writes 4428
JE/Stats/Memory/RSS size avg 43867136 bytes (41.83M)
JE/Stats/Memory/RSS size max 46411776 bytes (44.26M)
JE/Stats/Memory/RSS size max node 4
JE/Stats/Memory/RSS size min 42795008 bytes (40.81M)
JE/Stats/Memory/RSS size min node 3
JE/Stats/Memory/VM size avg 91016338 bytes (86.80M)
JE/Stats/Memory/VM size max 93835264 bytes (89.49M)
JE/Stats/Memory/VM size max node 1
JE/Stats/Memory/VM size min 90251264 bytes (86.07M)
JE/Stats/Memory/VM size min node 3
JE/Time elapsed 35 seconds
JE/Time working 35 seconds
JE/Worker/Finalize item microseconds { sum = 0, mean = 0, stdev = -- }
JE/Worker/Finalize task microseconds { sum = 20, mean = 0.689655, stdev = 1.93165 }
JE/Worker/Next item microseconds { sum = 103567, mean = 20.1846, stdev = 113.937 }
JE/Worker/Process item microseconds { sum = 34027935, mean = 6644.78, stdev = 4183.41 }
JE/Worker/Process item total microseconds { sum = 34027935, mean = 6644.78, stdev = 4183.41 }
TreeDelete[12] Job Summary
--------------------------
Final Job State Succeeded
Phase Executed
TreeDelete requires OneFS to perform a treewalk within the filesystem namespace as the first task, in order to determine how much work it will need to perform. For instance, a TreeDelete job starting at /ifs/temp will traverse the directory hierarchy down to the lowest-level subdirectories. For more complex TreeDelete configurations, the job will traverse all the configured policy paths, so it’s fair to say that TreeDelete can be a relatively metadata-heavy process.
As such, enabling metadata write acceleration (all metadata housed on SSDs) has the potential to speed up TreeDelete substantially. However, for optimal speed here, there are other considerations.
Layout can gain you a lot, provided you’re also smart about running multiple threads to do the deletions. If you have lots of smaller directories, delete performance is likely to be very good. If you have a few wide directories, it’s not likely to help much.
Be aware that, even though TreeDelete is multithreaded, if the deletion happens in a directory, it still requires an exclusive lock on the directory. This would slow the deletion down as the job’s worker thread will have to wait on getting a lock to do the deletion. So, if you have the available I/O, you can literally delete files stored in ten separate directory ten times as quickly deleting the same files from a single directory.
So ‘manually’ spreading the delete load has the potential to be faster. Also, deleting large files is quite expensive in terms of free-space management. For files larger than a tunable threshold in size, each node will, by default, spin up a background thread to delete the file.
A general rule is:
More directories = more TreeDelete parallelism = better performance.
Running the TreeDelete job at high impact, rather than the default medium, will increase the number of threads. However, this is only recommended for an idle cluster – not if there is other work happening.
Another option for data housekeeping on a cluster is using TreeDelete to maintain a common ‘recycle bin’. This can be done by create a directory like /ifs/recycle for users to dump their unwanted files in, via Windows file explorer, or the UNIX/linux ‘mv’ command, etc. Then periodically manually run or set up a cron job for the treedelete job. For example:
# isi job jobs start treedelete --path /ifs/recycle --priority 10 --policy low
Note that the TreeDelete job will also delete the /ifs/recycle folder. If this is a problem, you can also:
- Set an advisory quota on the parent directory, which will prevent it from being deleted. However, this requires SmartQuotas to be licensed on the cluster.
- Add a cron job to recreate the recycle directory after the TreeDelete has completed.
- Use a symlink for the current recycle directory. When you want to empty it, switch the symlink to a new empty directory, then start the job to delete the old directory.
- Add subdirectories to the parent directory and just delete the ‘junk’ subdirectory. Ie. /ifs/recycle/junk1, /ifs/recycle/junk2, /ifs/recycle/junk3. This will potentially have the added benefit of more directory parallelism, and potentially better performance.
Be aware of the potential for file name collisions in the recycle bin. If two users both attempt to move files with the same name the recycle bin, the second one will require delete permissions to the first one.
In order to immediately reclaim the deleted file space from a TreeDelete job run, it may be necessary to remove all snapshot policies in that project path, delete those snapshots, then move the project into the recycle bin and let TreeDelete take over. Even the moving data to the recycle bin tree can force SnapshotIQ to preserve blocks if the snap existed before prior to the data being moved. To delete a project entirely, you must remove all snaps associated with that tree to actually get all of your space back. This can potentially include snapshots taken higher in the tree. Be aware that some other jobs, such as the FilesystemAnalyze, ChangelistCreate, etc, can keep a snapshot at the /ifs level sitting around to make incremental FSA jobs run faster.
As mentioned above, be aware that TreeDelete will not, by default, delete a directory that is the root directory of a quota. However, TreeDelete in OneFS 8.2 and later contains a flag to remove the top level quota, if one exists, so the final rmdir does not fail. For example:
# isi job jobs start treedelete –delete-quotas --path /ifs/recycle
It’s also fairly straightforward to write simple scripts to run TreeDelete. For example, the following shell command looks for subdirectories one level under the parent path, ‘/ifs/recycle’, and instructs TreeDelete to remove them:
# for i in `find /ifs/recycle -type d –depth 1`; do isi job jobs start treedelete --path $i; done
Another approach can be used in situations (ie. Windows environments) where the directory names can contain whitespace:
# find /ifs/recycle -type d –depth 1 -print0 | xargs -0 -I % isi job jobs start treedelete --path “%”
This command will also combine each line of the file into a single line and pass to the path argument.
Note that if you have more than 30 directories, the command will likely fail because the job engine cannot queue more than thirty jobs. However, when emptying out recycle bin(s), if you create a time-stamped sub-directory and move everything for deletion into it, and then TreeDelete this directory, the 30-job limit is avoided.
This is a common challenge across a range of verticals, and particular in the EDA realm, where there are a couple of creative solutions. In addition to custom tools, solution also include discovering the files via find and moving them to a /ifs/data/recycle/date/batch-number/…100,000 files. Treedelete can then be run on a schedule, one at a time per batch number, with low impact and off hours so as not to impact key work flow times.
For example, a TREEDELETE_OFF_HOURS job impact policy can be created, which might include ‘SAT 00:00 to Sun 00:00 AND MON 00:00 to 06:00 LOW’. The default impact of the job could then be reconfigured from MEDIUM to TREEDLETE_OFF_HOURS. This would mean that any time that a TreeDelete job is run without specifying ‘-o medium’, it would automatically inherit and execute the TREEDELETE_OFF_HOURS schedule.
When moving directories to a recycle bin, beware of not crossing quota domains. The performance impact will be significant since the quota traverse will require a copy, delete, and then the subsequent TreeDelete.
So there you have it – a couple of examples in which the TreeDelete job can simplify and improve the wall clock time for data removal.